Yesterday, Jensen Huang stood on stage at GTC and called OpenClaw “the operating system for personal AI.” He compared it to Linux, to Kubernetes, to HTML. He said every company needs an OpenClaw strategy.
He’s right. And his own announcement proves what’s missing.
What NemoClaw actually is
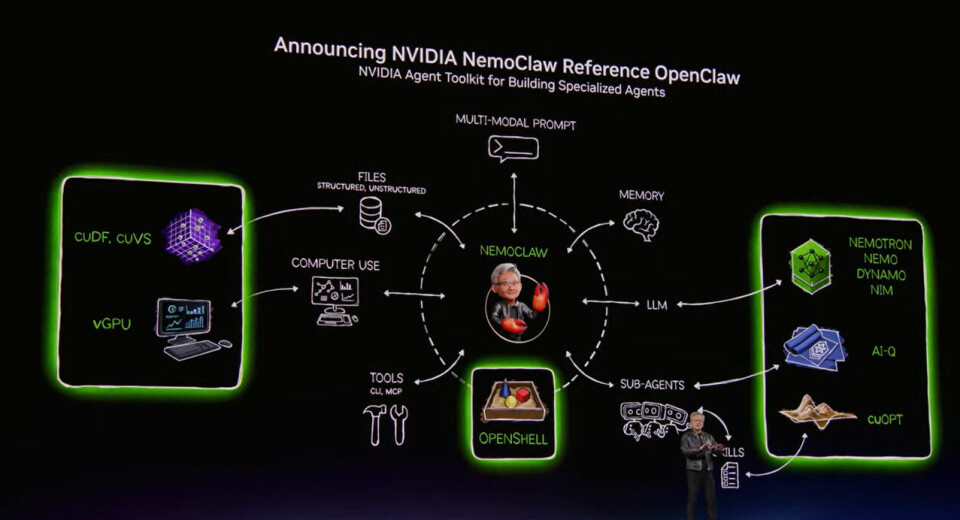
NVIDIA announced NemoClaw — an enterprise security layer for OpenClaw. It wraps agents in OpenShell sandboxes (Landlock, seccomp, network namespaces), enforces policy-based guardrails, and routes sensitive inference to local Nemotron models via a privacy router. It’s real, it’s open source, and it solves a real problem: enterprises need to know their agents aren’t going rogue.

NemoClaw answers the question: how do we safely run agents?
It does not answer: how do agents remember?
NemoClaw is explicitly stateless between sessions. No memory extraction. No knowledge graph. No session persistence. No identity continuity. It secures the runtime and trusts OpenClaw to handle everything else.
The problem is that OpenClaw’s memory is broken. And everyone knows it.
The memory crisis nobody’s solving
This isn’t an opinion. It’s a search query.
Reddit threads titled “OpenClaw Memory and Learning is a broken System and everyone knows this.” GitHub discussions with hundreds of comments on “OpenClaw Memory Is Broken By Default.” Blog posts documenting silent memory loss after twenty minutes of operation. A developer tweeting “Your OpenClaw agent is getting dumber every day and you have no idea.”
The technical failures are well-documented. Context compaction silently drops instructions. Memory storage is flat — 400-token chunks with 80-token overlap in SQLite, no relational structure. Cross-session persistence is effectively nonexistent. Microsoft and Salesforce research shows models that score 90%+ on single-turn tasks drop to 60% on multi-turn.
Jensen compared OpenClaw to Linux. But Linux ships with a filesystem. Linux has /home. OpenClaw doesn’t.
An operating system without persistent storage isn’t an operating system. It’s a bootloader.
The wrong answer to the right question
The industry noticed the memory problem. Their answer has been to give agents memory tools — “remember this,” “recall that,” “reflect on what you know.” Every major player does this. Mem0, Letta, Hindsight, LangMem, Sediment. They hand the agent a filing cabinet and call it memory.
Think about that for a second.
You’re trusting the LLM — the stateless reasoning engine that forgets everything between sessions — to decide what’s worth remembering. You’re asking the thing that has no memory to manage its own memory. It’s like asking someone with amnesia to maintain their own medical records.
This isn’t how memory works. You don’t consciously query a database to remember your coworker’s name. You don’t run a search when you sit down at your desk to figure out what project you’re working on. That context surfaces because it’s relevant — ambient, automatic, already there before you need it.
Giving an agent a remember() tool is useful for discrete lookups. Searching for a file, finding a skill definition, looking up an API reference. But that’s reference material, not memory. Picking up a book isn’t remembering. It’s research.
Memory is what you already know when you walk into the room.
A different architecture
Signet doesn’t give agents memory tools. The agent is not in the loop.
Here’s what happens instead. A session ends. The distillation engine — a local LLM running outside the conversation — reviews what happened and extracts structured knowledge. Not “save the transcript.” Distill. Atomic facts are identified, checked against what’s already known, and filed: new insight, updated fact, outdated entry replaced, or noise skipped. The agent was never involved. It didn’t decide what to keep. It didn’t call a tool.
Next session starts. Before the first prompt reaches the model, the system has already assembled context. The knowledge graph is traversed — entities, aspects, constraints, dependencies — and the relevant slice is injected into the conversation. The agent doesn’t search for what it needs. It arrives already knowing.
This is the difference between a filing cabinet and an actual mind. One requires you to open drawers. The other just has the context when the moment calls for it.
The part nobody else is building
We’re training a predictive model. Not a search engine — a neural network that runs alongside the LLM and anticipates what context will be needed, before the agent asks, before a prompt is submitted.
It’s trained on your interaction patterns. Which memories actually helped in past sessions. What time of day certain projects matter. Which entity relationships are relevant to your current work. The signal isn’t synthetic — it’s the agent itself reporting what was useful, on every prompt, accumulated across real sessions.
Your weights never leave your machine. The model is unique to you. And with consent, anonymized training signals feed a shared base model that ships with every new install — so the next person’s agent starts smart on day one, then gets sharper for them specifically. Federated learning applied to agent memory.
Nobody else has this data. Nobody else is collecting first-order ground truth about what memories actually matter in real agent sessions. The rest of the market is building better search. We’re building a system that knows what you need before you search.
Where the layers sit
When Linux became the enterprise standard, the companies that won didn’t compete with Linux. They built the layers Linux was missing. Datadog built monitoring. HashiCorp built infrastructure automation. Istio built the service mesh. They named the gap, positioned as the essential complement, and let the platform’s adoption carry them.
The same thing is happening now.
applications
agents
execution security ← NemoClaw
persistent cognition ← Signet
models
hardwareNemoClaw secures the runtime. Signet provides the mind. They’re not competing layers — they’re complementary. An agent running inside NemoClaw’s sandbox still has no memory between sessions, no identity continuity, no predictive context. An agent running with Signet but no sandbox has memory but no security guarantees.
The full stack needs both.
What “home directory” actually means
Jensen’s Linux analogy is more useful than he probably intended.
On Linux, /home is where your identity lives. Your dotfiles, your SSH keys, your shell configuration, your editor preferences. You can reinstall the OS, swap the kernel, change distributions entirely — and your home directory carries your identity forward.
Signet is ~/.agents/. Plain files. Version-controlled. Human-readable.
~/.agents/
agent.yaml # runtime config
AGENTS.md # operating instructions
SOUL.md # personality and voice
IDENTITY.md # structured identity
USER.md # operator profile
MEMORY.md # synthesized working knowledge
skills/ # installed capabilities
.secrets/ # encrypted secret storeSwap the model. Swap the harness. Switch from Claude Code to OpenClaw to OpenCode. The agent persists. Same knowledge, same personality, same secrets. The model is a guest in the agent’s home — it reads what it needs, does its work, and writes back what it learned.
This isn’t a feature. It’s an architecture that treats agent continuity as a first-class concern, not an afterthought bolted onto a stateless system.
The timing
The agent ecosystem just declared itself modular. NVIDIA validated the layered model by building a security layer on top of an open runtime. That’s the same bet we made when we built Signet as a cognitive layer that plugs into any harness.
Jensen is right that every company needs an OpenClaw strategy. But an OpenClaw strategy without persistent cognition is a strategy for agents that start over every morning. Agents that lose context mid-conversation. Agents that can’t learn from yesterday’s mistakes.
The OS moment is here. The question is whether the stack ships with a home directory or not.
We think it should.
Signet is open source and runs locally. Install it or read the code.